



3 月 18 日,昆仑万维小心开源首款工业界多模态想维链推理模子 Skywork-R1V泷川雅美快播,开启多模态想考新期间。继 Skywork-R1V 初次见效结束“强文本推理才智向视觉模态的挪动”之后,昆仑万维再度发力,今天小心开源多模态推理模子的全新升级版块 —— Skywork-R1V 2.0(以下简称 R1V 2.0) 。
01
R1V 2.0 性能全面进步并开源,视觉与文本推理才智双管王人下
Skywork-R1V 2.0 是面前最平衡兼顾视觉与文本推理才智的开源多模态模子,该多模态模子在高考理科贫苦的深度推理与通用任务场景中均弘扬优异,确切结束多模态大模子的“深度 + 广度”和解。升级后的 R1V 2.0 模子颇具亮点:
-华文场景领跑:理科学科题目(数学/物理/化学)推理后果拔群,打造免费AI解题助手;
-开源巅峰:38B 权重 + 时间论说全面开源,鞭策多模态生态诞生;
-时间立异标杆:多模态奖励模子(SkyworkVL Reward) 与 混杂偏好优化机制(MPO),全面进步模子泛化才智;聘用性样本缓冲区机制(SSB),破损强化学习“上风散失”瓶颈。
在多个巨擘基准测试中,R1V 2.0 相较于 R1V 1.0 在文本与视觉推理任务中均结束权贵跃升。不管是专科规模任务,如数学推理、编程竞赛、科学分析,也曾通用任务,如创意写稿与绽开式问答,R1V 2.0 都呈现出极具竞争力的弘扬:
-在 MMMU 上赢得 73.6 分,刷新开源 SOTA 记载;
-在 Olympiad Bench 上达到 62.6 分,权贵进步其他开源模子;
-在 MathVision、MMMU-PRO 与 MathVista 等多项视觉推理榜单中均弘扬优异,多项才智已可忘形闭源营业模子,号称面前开源多模态推理模子中的杰出人物。
在与开源多模态模子的对比中,R1V 2.0 的视觉推理才智(在广漠开源模子里)脱颖而出。

如下图所示,R1V2.0 也展现出忘形营业闭源多模态模子的实力。
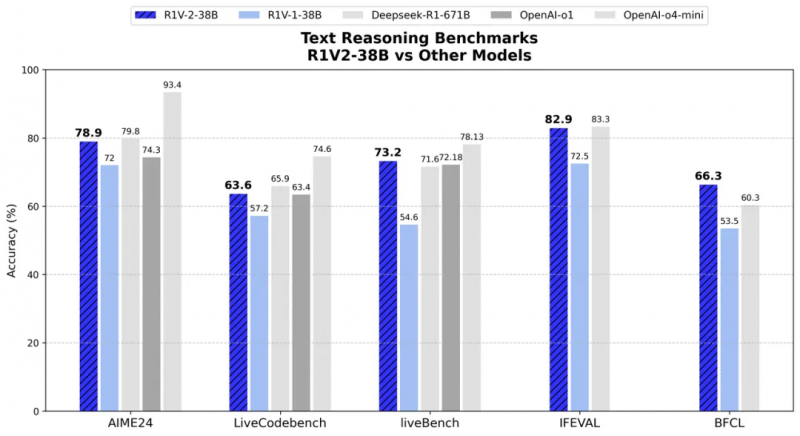
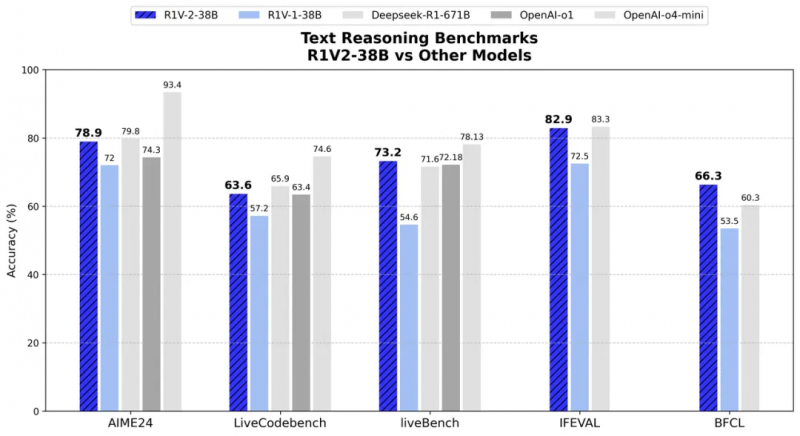
而在文本推理方面,在 AIME2024 和 LiveCodeBench 等挑战中,R1V 2.0 辩认赢得了78.9 分和 63.6 分,展现出了东说念主类各人级数学与代码领略才智。在与专用文本推理模子对比中,R1V2.0 雷同展现出超卓的文本推理才智。
02
时间亮点一:推出多模态奖励模子 Skywork-VL Reward,全面开源
自 R1V 1.0 开源以来,昆仑万维团队收成了来繁荣众开辟者与估量者的平凡反馈。在模子推理才智权贵进步的同期,团队也发现,过度靠拢于推理任务的考验,会规则模子在其他老例任务场景下的弘扬,影响全体的泛化才智与通用弘扬。
为结束多模态大模子在“深度推理”与“通用才智”之间的最好平衡,R1V 2.0 引入了全新的「多模态奖励模子 Skywork-VL Reward」及「规矩驱动的混杂强化考验机制」。在权贵增强推理才智的同期,进一步领悟了模子在多任务、多模态场景中的平稳弘扬与泛化才智。
Skywork-VL Reward,开启多模态强化奖励模子新篇章:
面前,行业中多模态奖励模子的短缺,已成为强化学习在 VLM(Vision-Language Models)规模进一步发展的要道瓶颈。
现存奖励模子难以准确评价跨模态推理所需的复杂领略与生成经由。为此,昆仑万维推出了 SkyworkVL Reward模子,既可为通用视觉言语模子(VLM)提供高质料奖励信号,又能精确评估多模态推理模子长序列输出的全体质料,同期也不错算作并行线上推理最优谜底聘用的利器。
这种才智使得 Skywork-VL Reward 模子在多模态强化学习任务中具有平凡的适用性,促进了多模态模子的协同发展:
-跨模态引颈者:最初提倡多模态推理与通用奖励模子,鞭策多模态强化学习;
-榜单标杆:在视觉奖励模子评测中名列第一,7B 权重与时间论说全面开源;
-信号全障翳:维持从漫笔本到长序列推理的多元化奖励判别。
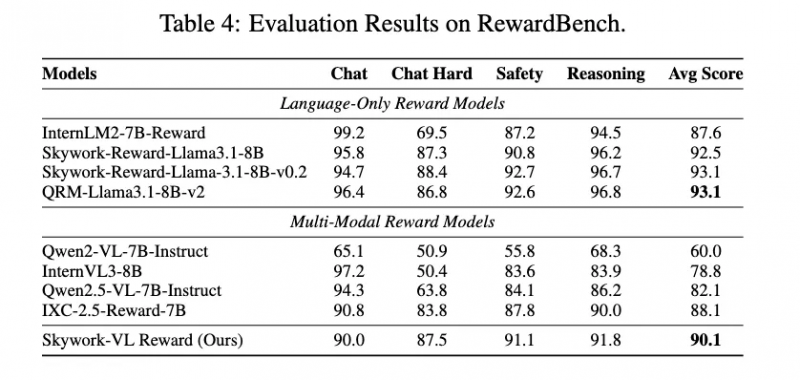
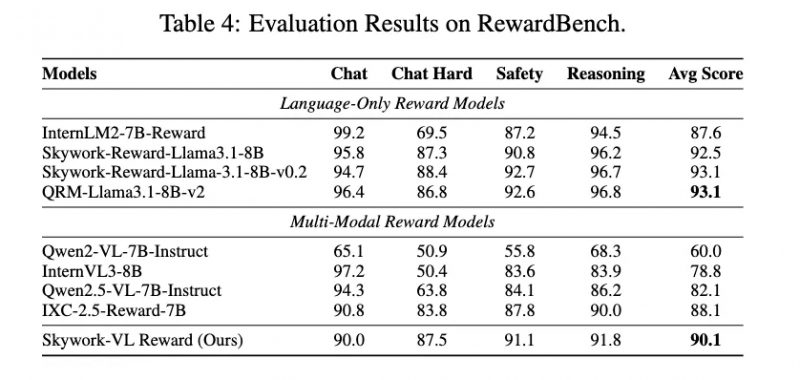
Skywork-VL Reward 在多个巨擘评测榜单中弘扬优异:在视觉奖励模子评测榜单 VL-RewardBench 中赢得了 73.1 的SOTA成绩,同期在纯文本奖励模子评测榜单 RewardBench 中也斩获了高达 90.1 的优异分数,全面展示了其在多模态和文本任务中的弘远泛化才智。
为回馈社区和行业,团队也将 Skywork-VL Reward 完好开源。
03
时间亮点二:引入多重优化计谋进步中枢后果
永久以来,大模子考验濒临“深度推理进步”与“通用才智保抓”的难以兼得贫苦。为惩处这一“推理–通用”的才智跷跷板问题,以及惩处通用问题莫得径直可考证的谜底的挑战,R1V 2.0 引入了 MPO(Mixed Preference Optimization,混杂偏好优化) 机制,并在偏好考验中充分阐扬 Skywork-VL Reward 奖励模子的率领作用。
和 R1V 1.0 想路访佛,咱们使用提前考验好的 MLP 适配器,径直将视觉编码器 internVIT-6B 与原始的强推理言语模子 QwQ-32B 麇集,造成 R1V 2.0-38B 的运行权重。这么一来,R1V 2.0 在启动即具备一定的多模态推理才智。
在通用任务考验阶段,R1V 2.0 借助 Skywork-VL Reward 提供的偏好信号,诱骗模子进行偏好一致性优化,从而确保模子在多任务、多规模下具备精粹的通用安妥才智。实考解说,Skywork-VL Reward 灵验结束了推理才智与通用才智的协同进步,见效结束“鱼与熊掌兼得”。
在考验深度推理才智时,R1V 2.0 在考验中吸收了 基于规矩的群体相对计谋优化GRPO(Group Relative Policy Optimization) 智商。该计谋通过同组候选反应之间的相对奖励比拟,诱骗模子学会更精确的聘用和推理旅途。
R1V 2.0 所吸收的多模态强化考验决议,标识着大模子考验范式的又一次伏击变嫌,也再次考证了强化学习在东说念主工智能规模无法撼动的地位。通过引入通用性更强的奖励模子 Skywork-VL Reward,以及高效平稳的样本欺诈机制 SSB,咱们不仅进一步进步了R1V系列模子在复杂任务中的推理才智,同期也将开源模子跨模态推理泛化才智进步到了全新高度。
R1V 2.0 的出身,不仅鞭策了开源多模态大模子在才智鸿沟上的破损,更为多模态智能体的搭建提供了新的基座模子。
04
面向AGI的抓续开源
最近一年以来,昆仑万维已继续开源多款中枢模子:
开源系列:
1. Skywork-R1V 系列:38B 视觉想维链推理模子,开启多模态想考期间;
2. Skywork-OR1(Open Reasoner 1)系列:华文逻辑推理大模子,7B和32B最强数学代码推理模子;
3. SkyReels系列:面向AI短剧创作的视频生成模子;
4. Skywork-Reward:性能超卓的全新奖励模子。
这些技俩在 Hugging Face 上广受宽宥,激励了开辟者社区的平凡祥和与深刻商榷。
咱们深信,开源驱动立异,AGI 终将到来。
正如 DeepSeek 等优秀团队所展现的那样,开源模子正逐步弥合与闭源系统的时间差距,乃至结束非凡。R1V 2.0 不仅是面前最好的开源多模态推理模子,亦然咱们迈向 AGI 路上的又一伏击里程碑。昆仑万维将赓续秉抓“开源、绽开、共创”的理念泷川雅美快播,抓续推出进步的大模子与数据集,赋能开辟者、鞭策行业协同立异,加快通用东说念主工智能(AGI)的结束程度。
-->